The Production Pain
Your ML team ships a model update. Inference costs spike 40% overnight. No one knows why until someone digs through deployment configs and finds a batch size regression. Meanwhile, the on-call engineer is debugging a latency alert that turns out to be GPU memory fragmentation from a change three deployments ago.
This is how AI infrastructure pain shows up day-to-day: not dramatic failures, but compounding operational debt. GPU idle time burns budget. Inconsistent deployments create debugging archaeology. Evaluation regressions slip through because there’s no systematic way to catch them. Prompt versions scatter across notebooks, Slack threads, and someone’s local machine.
The business consequences are real: cost volatility, slower iteration cycles, and reliability incidents that erode trust. Open source can be leverage here—but only if it’s built with the same discipline you’d apply to any production system.
What “AI Infrastructure” Means in Practice
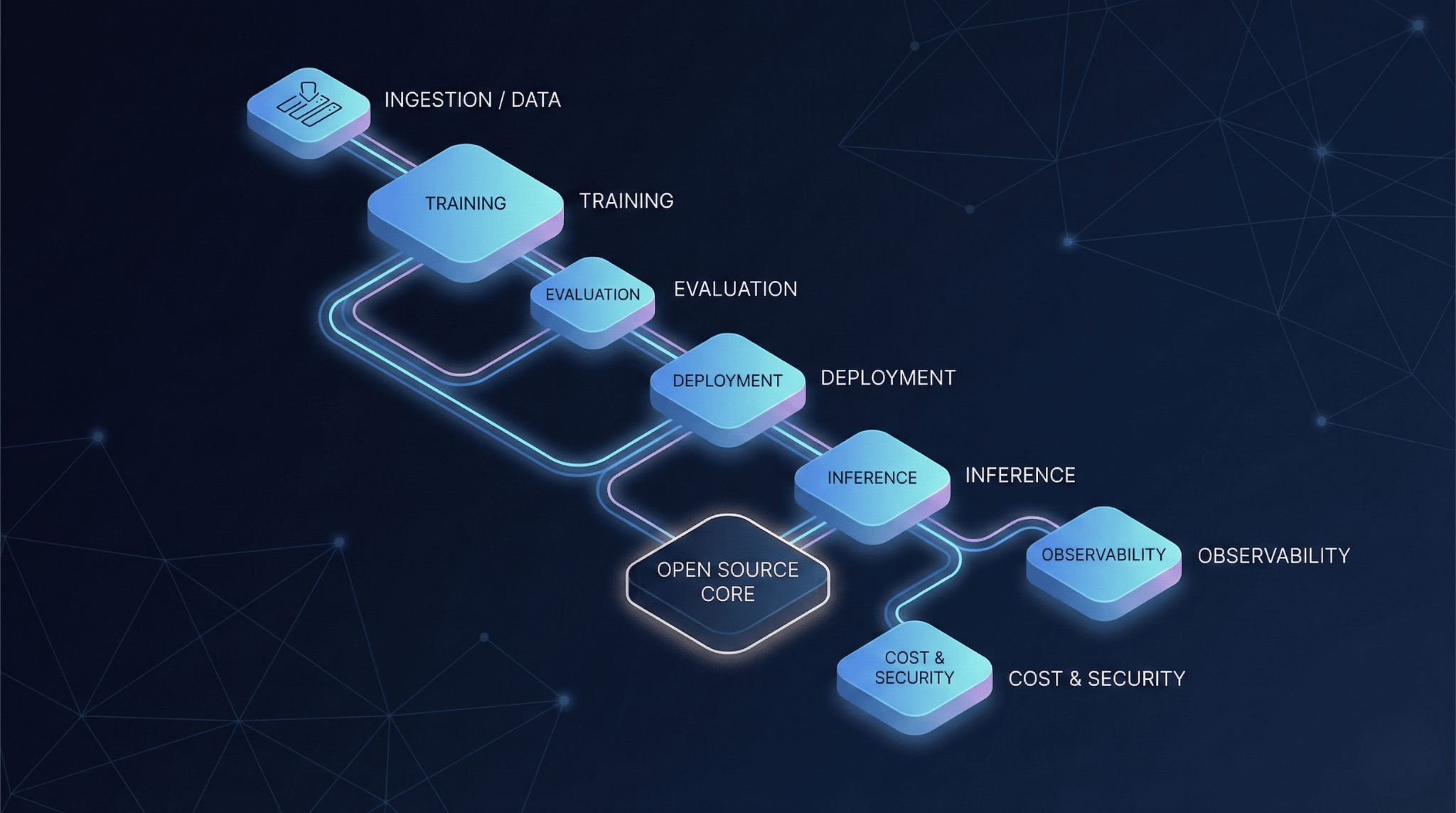
In practical terms, AI infrastructure is about repeatability and control across a stack: data pipelines, training and inference systems, model registries, evaluation harnesses, deployment tooling, observability, cost controls, and security boundaries.
The goal isn’t sophistication—it’s predictability. When you deploy a model, you should know what you’re deploying, how it will behave, what it will cost, and how to roll it back safely. Infrastructure is the machinery that makes AI systems predictable enough to operate.
Choosing the Right Wedge
The most adoptable open-source infrastructure projects solve one narrow problem exceptionally well. We call this the wedge—a focused entry point with clear boundaries and measurable impact.
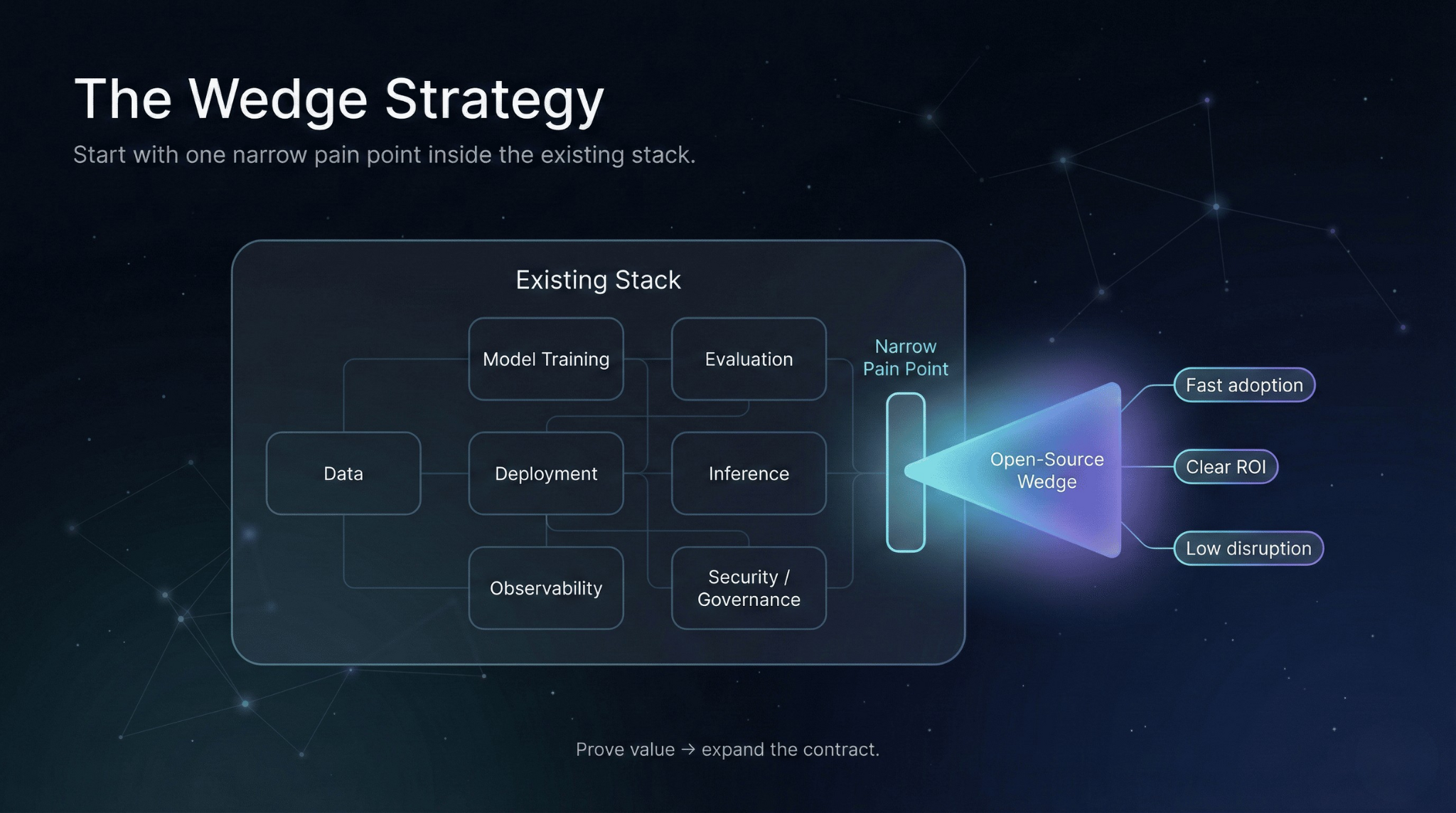
A good wedge has four characteristics: it addresses high-frequency pain (something teams hit weekly, not quarterly), offers an explicit interface contract, produces measurable outcomes, and integrates with existing stacks rather than requiring wholesale adoption.
To keep this concrete, consider a practical wedge many teams feel immediately: deployment configuration validation + drift detection with cost attribution for inference. It doesn’t require re-architecting your ML platform. It plugs into CI/CD, runs as a gate, and makes two things visible that often aren’t: what changed and what it costs.
Other effective wedges follow the same pattern: a lightweight evaluation harness that plugs into CI pipelines, a prompt/versioning system with deterministic hashing and rollback, or a minimal tracing layer that standardizes context propagation across agent workflows. The strategy is consistent: narrow scope, strong contracts, incremental adoption.
Design Principles for Production-Grade OSS
Building infrastructure that teams will actually run in production requires explicit design commitments.
Explicit contracts
Define interfaces precisely. What inputs does the system accept? What outputs does it guarantee? What are the boundary conditions? Ambiguity in contracts becomes integration bugs, and integration bugs become incidents.
Deterministic behavior (or controllable randomness)
Where randomness exists (sampling, load balancing), make it controllable and reproducible. Engineers debugging production issues need to replay scenarios exactly.
Safe defaults and clear failure modes
Out-of-the-box configuration should be conservative. When the system fails, it should fail loudly and predictably—not silently corrupt state or produce misleading outputs. Failure modes should be testable, not hypothetical.
Observability by default
Expose metrics, structured logs, and trace context from day one. Teams can’t operate what they can’t measure. This isn’t optional polish; it’s core functionality.
Performance and cost controls
Provide explicit controls for batching, caching, resource scheduling, and quality–cost tradeoffs. Production teams need to tune behavior without forking your code.
Security posture
Handle secrets properly (no “env var leaks” as a design). Implement least-privilege defaults, RBAC-friendly patterns, and minimize data exposure. Document the threat model you considered and where your boundaries are (what you do and do not protect against).
The Boring Parts That Determine Adoption
Documentation determines adoption more than features. Structure it in layers: a quickstart that gets someone running in ten minutes, conceptual docs explaining the “why,” recipes for common workflows, and troubleshooting guides for known failure modes.
Ship examples that reflect real workflows, not toy demos. Maintain a compatibility matrix showing which versions work with which dependencies. Establish a versioning policy and stick to it.
Tests are part of the trust contract. Unit tests validate logic. Integration tests validate contracts. End-to-end tests validate workflows. CI that runs on every PR signals that you treat quality as a first-class requirement.
Release notes should explain what changed, why it matters, and what users need to do about it. Upgrade guidance prevents silent breakages—the fastest way to make teams pin to old versions forever.
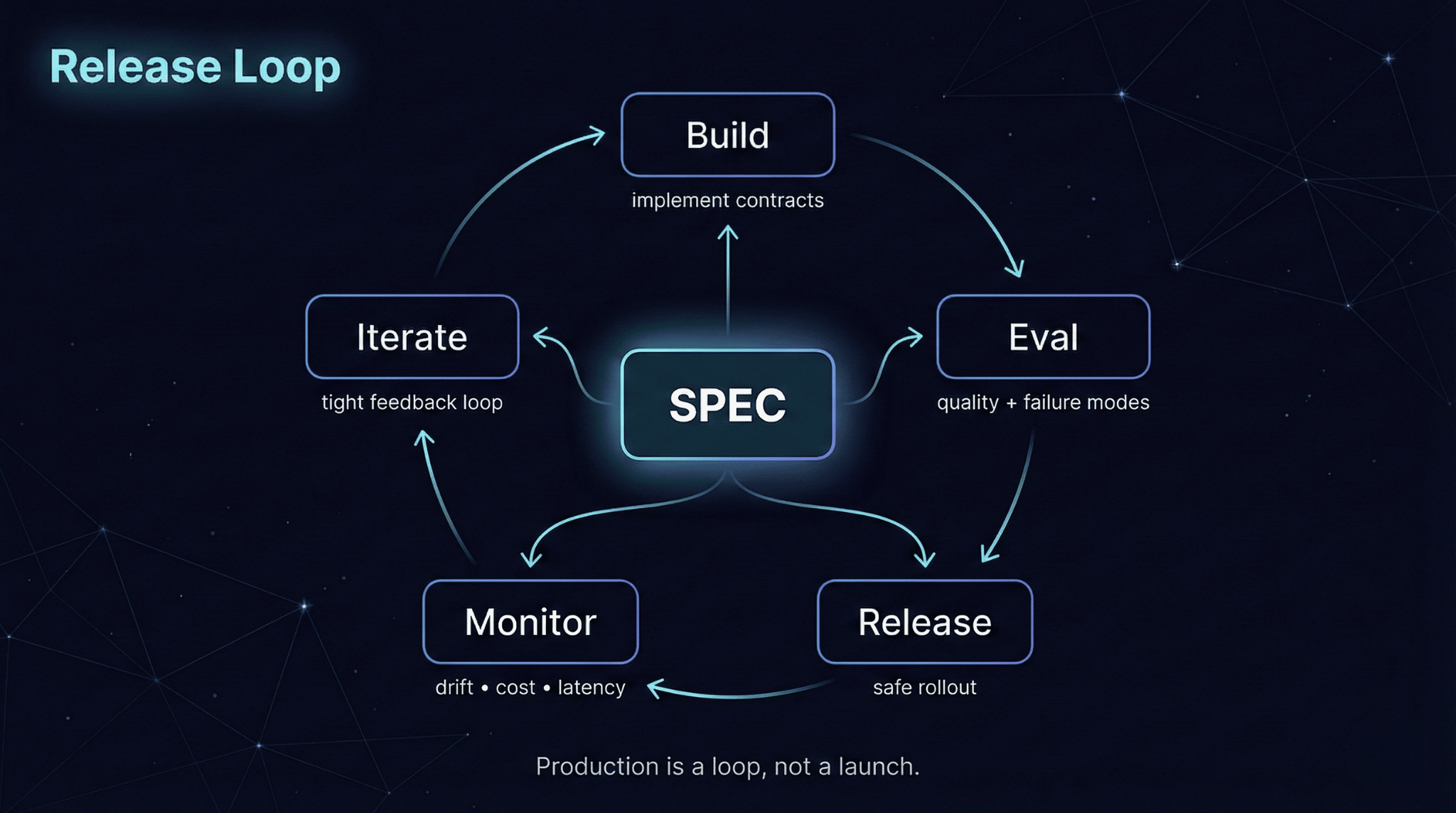
How Teams Actually Adopt (and What “Production-Ready” Looks Like)
Adoption follows a predictable path: run locally, integrate in development, deploy to staging with guardrails, then production with SLOs. Design your system to support each stage.
A practical adoption flow looks like this:
Local: validate the interface and basic behavior
Dev: integrate into CI/CD or a dev environment with sample data
Staging: run with representative traffic + alerting enabled
Production: enforce SLOs, rollout strategy, and automated rollback
Before production, teams should be able to confirm the following (a minimal checklist):
Health checks and readiness probes exist
Metrics/logs/traces integrate with their observability stack
Failure modes are documented and exercised in tests
Rollback (and preferably canary) procedures are defined
Resource limits/quotas are configured and validated
Access controls and secrets handling follow least privilege
Alert thresholds map to SLOs (not “noise metrics”)
Rollout deserves explicit attention. Even a small wedge should support safe deployment patterns: canary rollouts, gradual ramp, or shadow mode—plus automatic rollback when guardrails are violated. Production readiness isn’t only correctness; it’s controlled change.
Sustainability: Why OSS Projects Survive or Rot
Open-source projects die from neglect, not competition. Managing issues and PRs, maintaining a public roadmap, and establishing contribution guidelines are ongoing work, not launch activities.
Commit to a backward compatibility philosophy. Breaking changes are sometimes necessary, but they should be rare, communicated early, and accompanied by migration paths. Nothing kills adoption faster than upgrades that break production without a clear exit route.
A Brief Scenario (What “Wedge” Impact Looks Like)
A platform team was spending 15+ hours monthly debugging inference cost spikes. The root cause was consistent: deployment config drift across environments.
After implementing a configuration validation layer with drift detection and cost attribution tags, debugging time dropped to under 2 hours monthly. p95 latency variance decreased 35% as a side effect of catching misconfigurations before deployment.
The tool wasn’t complex. It was narrow, well-tested, and observable—and it changed the operational experience: from guessing to measurement, from firefighting to controlled iteration.
Closing
Open source in infrastructure isn’t about code generosity. It’s about operational clarity. A good OSS project earns trust through explicit contracts, predictable behavior, production-grade documentation, and the discipline to maintain compatibility over time.
The measure of success isn’t GitHub stars. It’s whether a team can run your code in production, understand what it’s doing, adopt it incrementally, and operate it without constant firefighting. If your wedge helps teams reduce cost volatility, catch regressions earlier, and roll changes safely—it’s doing its job.