Why Document Extraction Fails in Production
Every document extraction demo looks impressive. Upload an invoice, watch the fields populate, see the JSON output appear. The accuracy numbers look promising—until you deploy to production and encounter your third vendor's invoice format, a faxed purchase order from 1997, or a multi-page contract with nested tables.
The gap between demo and production is where most extraction projects stall. The hidden costs accumulate quickly: manual review queues that never shrink, exception handling workflows that consume engineering time, compliance risks from undetected errors, and vendor lock-in that makes switching painful.
The solution isn't finding the "best" framework. It's selecting an approach based on your actual constraints—document variability, accuracy requirements, operational capacity, and risk tolerance—rather than benchmark claims or feature lists.
Defining the Contract
Before evaluating frameworks, establish what document extraction actually means for your system.

Inputs vary significantly: scanned PDFs with OCR artifacts, native digital PDFs with selectable text, photographs of documents, or mixed batches containing all three. Your framework choice depends heavily on which inputs dominate.
Outputs must be precisely specified: field-level extractions, structured tables with line items, nested hierarchies, or normalized values. Define your target schema before selecting tools.
Constraints determine viability: What accuracy threshold triggers human review? What latency is acceptable for downstream systems? What's your cost ceiling per document? How do you handle PII, and what audit trail do you need?
Failure modes must be designed for, not discovered later: How does the system signal low confidence? What happens when required fields are missing? How do you detect and handle hallucinated values? When does a document route to human review?
Evaluation Criteria
When comparing extraction approaches, assess these dimensions systematically.
Template variability tolerance. How well does the approach handle new document layouts without retraining or reconfiguration? This is often the deciding factor between rule-based and learning-based systems.
Table extraction robustness. Tables with merged cells, spanning headers, or implicit structure break many extraction pipelines. Test this specifically with your worst-case documents.
Confidence scoring and calibration. Does the system provide meaningful confidence scores? More importantly, are those scores calibrated—does 90% confidence actually mean 90% accuracy? Uncalibrated scores are operationally useless.
Determinism and audit trail. Given the same input, does the system produce the same output? Can you trace why a specific value was extracted? Regulatory environments often require this.
Latency and cost predictability. Batch processing tolerates variable latency; real-time workflows don't. API-based services incur per-document costs that compound at scale.
Integration complexity. How does the extraction component connect to your existing workflow systems, databases, and exception handling processes? A technically superior extractor that can't integrate is worthless.
Data privacy and compliance. Where is document data processed and stored? Does the solution support on-premises deployment if required? How is PII handled?
Maintainability. When a new document type arrives—and it will—what's the effort to support it? Days of labeling, hours of prompt engineering, or minutes of rule writing?
Comparing Approaches
OCR + Rules Pipeline
Best for stable, predictable document formats with consistent layouts. If you process the same invoice template thousands of times, rules-based extraction after OCR is fast, cheap, and completely deterministic.
Not suitable for variable templates or documents requiring interpretation. Fails brittlely when layouts shift even slightly. Maintenance burden grows linearly with document types.
Layout-Aware ML Models
Best for moderate template variability where documents share structural patterns (invoices, receipts, forms) but vary in specific layouts. These models learn spatial relationships between fields.
Requires labeled training data for new document categories. Performance degrades on documents that differ significantly from training distribution. Confidence scores vary in calibration quality.
LLM-Based Extraction with Structured Outputs
Best for documents requiring reasoning—interpreting ambiguous fields, handling free-form text sections, or extracting from documents without consistent structure.
Introduces hallucination risk and non-determinism. Latency and cost are higher than traditional approaches. Requires robust validation layers to catch fabricated values. Prompt engineering becomes a maintenance surface.
Vision-Language Models (Multimodal)
Best for documents where layout, visual elements, and text interact—forms with checkboxes, documents with stamps or signatures, or heavily formatted materials.
Computationally expensive. Quality varies significantly across model providers. Still maturing for production use cases requiring high accuracy guarantees.
Hybrid: OCR + LLM + Validators
Best for complex extraction needs where you require both the reliability of traditional OCR and the reasoning capabilities of language models, with deterministic checks ensuring output quality.
Higher architectural complexity. Requires careful orchestration between components. But offers the best balance of capability and control for production systems.
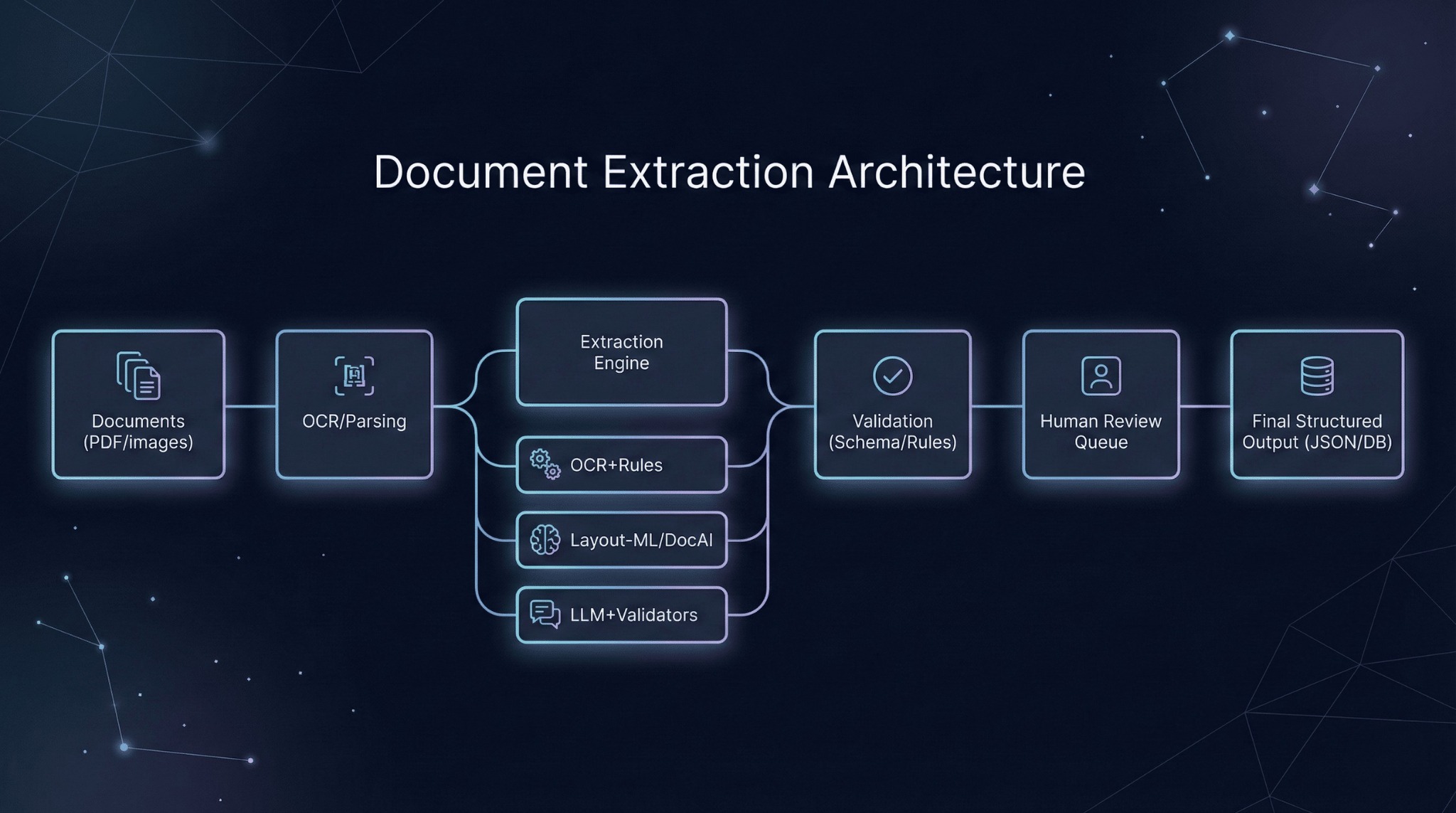
Recommended Architecture Pattern
For most enterprise deployments, a hybrid pipeline provides the right balance:
OCR layer handles text extraction with quality scoring. Normalization standardizes formats and corrects common artifacts. Extraction applies the appropriate method—rules for known templates, ML or LLM for variable documents. Validation enforces schema constraints, cross-field consistency, and business rules. Exception routing queues low-confidence documents for human review.
Invest heavily in validators. Schema enforcement catches structural errors. Business rule engines catch semantic errors. Cross-reference checks catch consistency errors. These deterministic layers are what make probabilistic extractors production-safe.
Maintain a golden test set of documents with known correct extractions. Run regression tests when changing prompts, updating models, or adding document types. Without this, you're operating blind.
Decision Guide
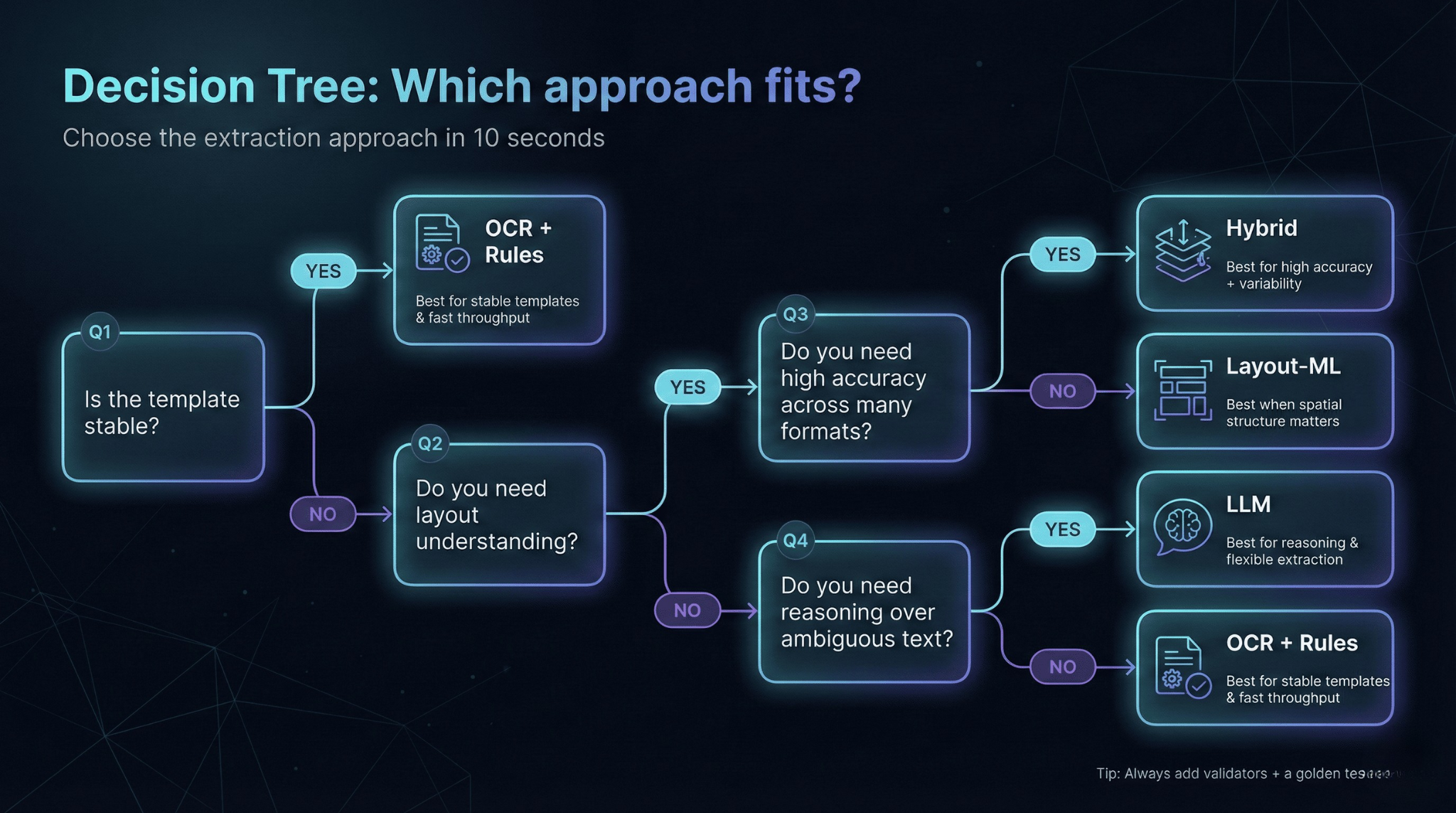
Choose OCR + rules when templates are stable and you control document sources.
Choose layout-aware ML when you have moderate template variety within document categories and can invest in training data.
Choose LLM-based extraction when documents require interpretation or reasoning, accepting higher cost and validation overhead.
Choose hybrid architectures when accuracy requirements are high and document variability is unpredictable.
Quick checklist before committing:
Have you tested with your worst 10% of documents, not your best?
Is confidence scoring calibrated against actual accuracy?
Do you have a defined human review workflow for exceptions?
Can you audit why any specific extraction decision was made?
Is your validation layer independent of your extraction layer?
The Principle
Document extraction is an operational system, not a model deployment. Success isn't measured by benchmark accuracy on clean test sets. It's measured by sustained accuracy on production traffic, controlled failure modes that route to humans appropriately, and audit trails that satisfy compliance requirements.
The framework matters less than the system around it.