The Failure Mode Nobody Talks About
Your engineers are competent. Your architecture is sound. Yet AWS costs climb month over month, and when finance asks what changed, nobody can answer with confidence.
This is the quiet failure mode of cloud operations at scale. Costs drift not because of negligence, but because optimization requires a system—not heroic one-time efforts. Teams ship features. Infrastructure scales to meet demand. Experiments become permanent. And the bill compounds.
The uncomfortable truth: cost optimization is governance, engineering, and feedback loops working together. Without all three, savings decay within quarters.
Define the Cost Contract First
Before optimizing anything, establish what you're actually optimizing for.
What We Optimize
Cost per workload: Cost per request, per customer, per pipeline run, or per 1,000 tokens processed. This is the unit economics that makes spend meaningful.
Predictable spend: Finance needs forecasting confidence. Engineering needs anomaly detection before surprises hit the invoice.
Guardrails that prevent regressions: Every optimization erodes without enforcement mechanisms.
The Constraints
Cost optimization doesn't exist in isolation. Every decision trades off against SLOs, security posture, compliance requirements, and delivery velocity. The goal is sustainable efficiency—not cheapest at any cost.
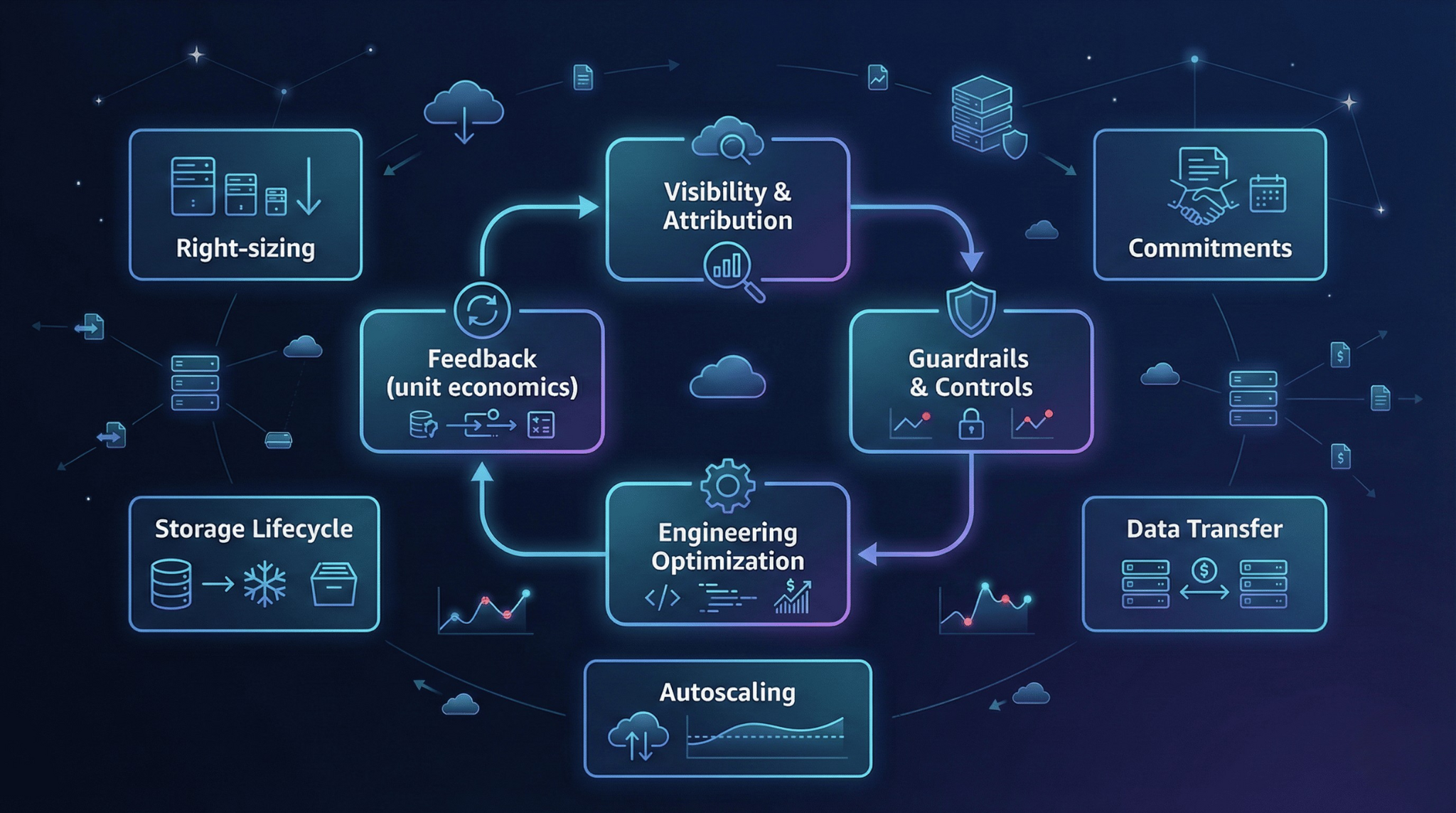
The Rockship Cost Optimization System
We approach cloud cost management as three interdependent layers. Skip any layer, and the system eventually fails.
Layer A: Visibility and Attribution
You cannot optimize what you cannot measure by workload.
This starts with a tagging strategy that maps resources to cost allocation units: team, service, environment, and tenant where applicable. AWS Cost and Usage Reports become the foundation for dashboards that answer "who spent what, where, and why."
The critical shift: move from aggregate spend to unit economics. Cost per request or cost per pipeline run transforms vague concern into actionable signal.
Layer B: Control and Guardrails
Visibility without enforcement is just expensive awareness.
Budgets with alerts establish thresholds. Anomaly detection catches unexpected spikes before month-end. Policy-as-code guardrails prevent known anti-patterns from reaching production.
Most importantly: cost review becomes part of change management. Infrastructure changes and significant PRs include cost impact as a review criterion—not as bureaucracy, but as engineering discipline.
Layer C: Engineering Optimization
This is where actual savings materialize—but only sustainably when Layers A and B are functioning.
Right-sizing, scheduling, storage lifecycle management, data transfer reduction, compute commitments, and architecture choices all live here. Each lever has context where it works and contexts where it backfires.
High-Leverage Optimization Levers
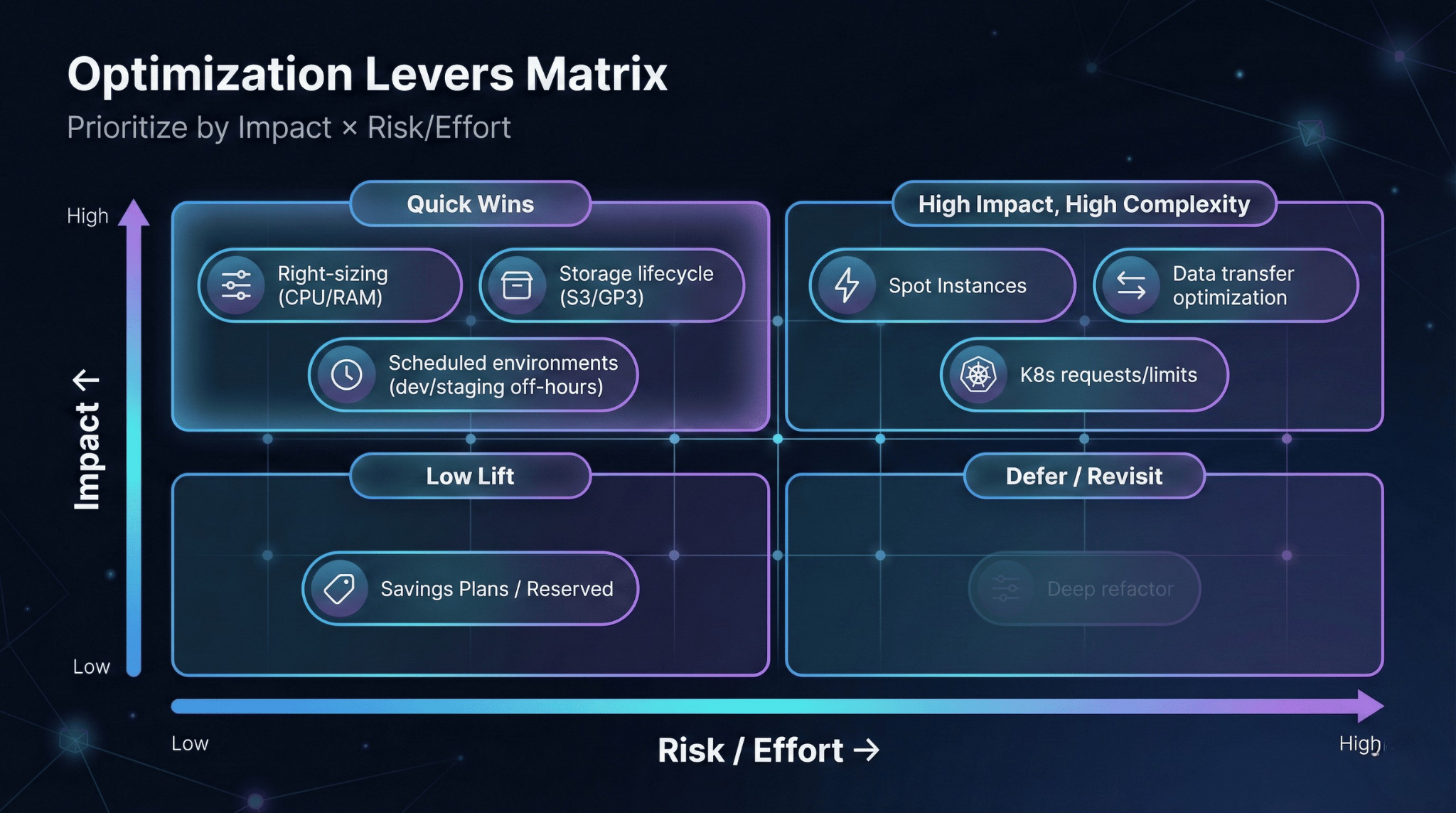
Right-Sizing and Autoscaling
What it is: Matching compute resources to actual utilization patterns rather than peak provisioning.
When it works: Workloads with measurable CPU and memory utilization data spanning representative time periods.
Trade-offs: Averages lie. A service averaging 30% CPU might spike to 95% during batch jobs. Right-sizing requires understanding percentile distributions, not means. Aggressive right-sizing without load testing creates production incidents.
Savings Plans and Reserved Instances
What it is: Commitment-based pricing that exchanges flexibility for discount.
When it works: Stable baseline workloads with predictable minimum utilization over 12-36 months.
Trade-offs: Over-commitment locks capital into resources you may not need. Under-commitment leaves savings on the table. The strategy requires regular review cycles—typically quarterly—to adjust commitment levels as workloads evolve.
Spot Instances with Interruption Handling
What it is: Using spare AWS capacity at significant discount with the trade-off of potential interruption.
When it works: Stateless workloads, batch processing, CI/CD runners, and any architecture designed for graceful degradation.
Trade-offs: Without proper interruption handling and workload distribution, spot terminations cascade into outages. This lever requires architectural investment before it becomes safe.
Storage Lifecycle and Hygiene
What it is: Tiering S3 objects by access pattern, tuning EBS volumes (gp3 offers better price-performance than gp2 in most cases), and enforcing snapshot retention policies.
When it works: Any environment with data that ages or becomes infrequently accessed.
Trade-offs: Aggressive lifecycle policies can move data to cheaper tiers before access patterns stabilize, creating retrieval costs that exceed storage savings.
Data Transfer Architecture
What it is: Reducing cross-AZ traffic, optimizing NAT gateway usage, and architecting for data locality.
When it works: Workloads with significant inter-service communication or external data egress.
Trade-offs: Data transfer optimization often requires architectural changes that compete for engineering bandwidth with feature work. The ROI calculation must include opportunity cost.
Container Cost Hygiene
What it is: Setting appropriate resource requests and limits, enabling efficient bin packing, and using differentiated node pools for workload types.
When it works: Any Kubernetes environment where pods are over-provisioned or nodes are underutilized.
Trade-offs: Aggressive limits cause OOM kills and throttling. Conservative requests waste capacity. This requires iterative tuning with production telemetry.
Scheduled Environments
What it is: Shutting down non-production environments outside working hours and using ephemeral environments for testing.
When it works: Development, staging, and QA environments that don't require 24/7 availability.
Trade-offs: Adds operational complexity for teams working across time zones or needing ad-hoc access.
Observability for Cost
What it is: Treating cost as a metric alongside latency, errors, and throughput—with anomaly detection and unit economics tracking.
When it works: Organizations mature enough to instrument cost attribution into their observability stack.
Trade-offs: Requires investment in tooling and cultural alignment to make cost a shared engineering concern.
Implementation Roadmap
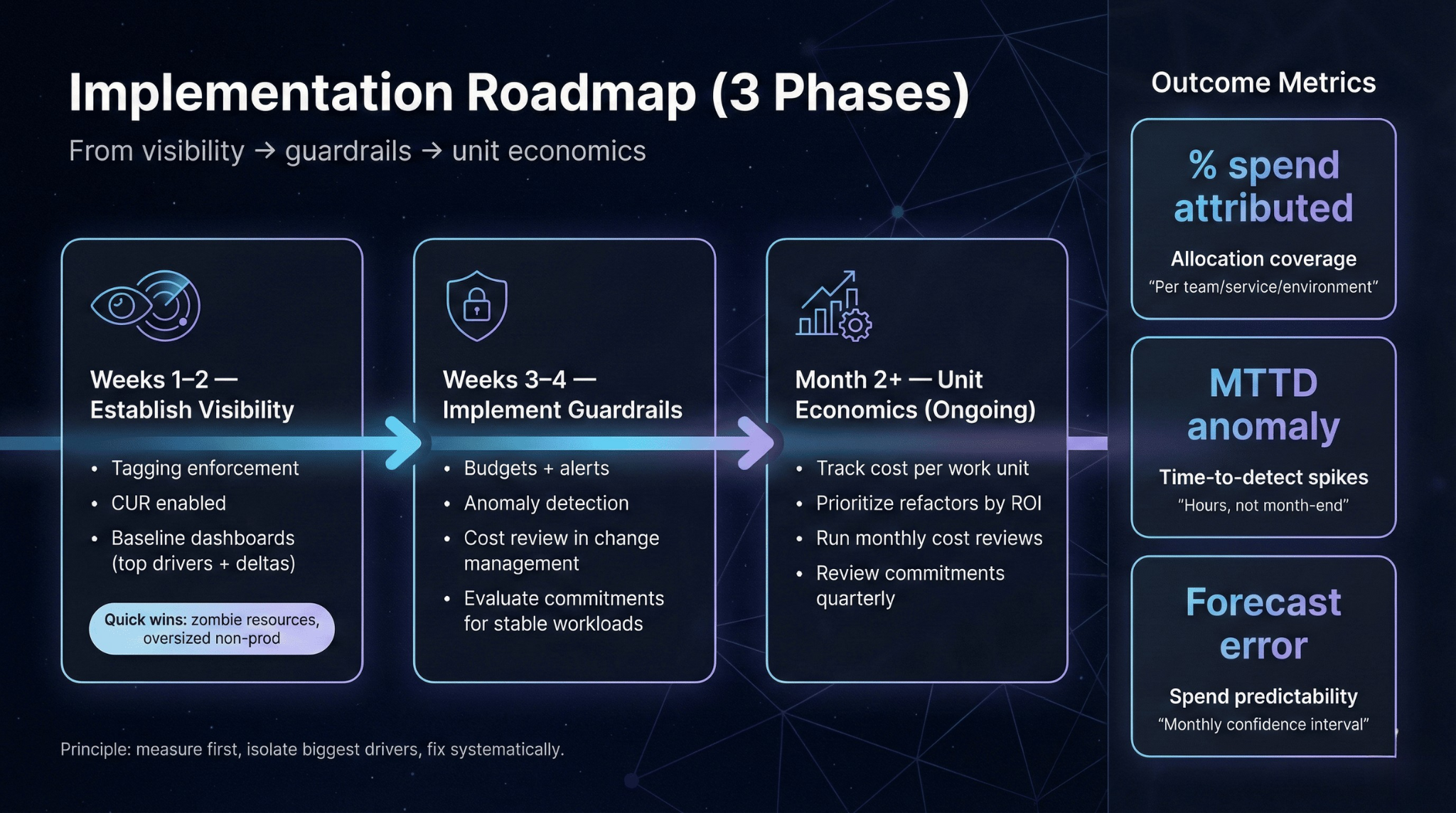
Weeks 1–2: Establish visibility. Tagging enforcement, CUR enabled, baseline dashboards (top drivers + deltas). Quick wins: zombie resources, oversized non-prod.
Weeks 3–4: Implement guardrails. Budgets + alerts, anomaly detection, cost review in change management, evaluate commitments for stable workloads.
Month 2+ (ongoing): Develop unit economics. Track cost per work unit, prioritize refactors by ROI, run monthly cost reviews, review commitments quarterly.
The principle: measure first, isolate the biggest drivers, fix systematically.
Mini Scenario
Before: A platform team faces 15% month-over-month cost growth. Top drivers are unclear. Finance requests forecasting; engineering lacks attribution.
Actions: Implement comprehensive tagging (2 weeks). Right-size development environments using utilization data (illustrative: 40% compute reduction in non-prod). Purchase Savings Plans covering 60% of stable baseline.
After: Cost growth flattens. Anomaly detection catches a runaway batch job within hours instead of at month-end. Finance receives forecasts with confidence intervals.
Production Checklist
All resources tagged with team, service, environment, and cost center
Budgets and anomaly alerts configured for each cost allocation unit
Cost review included in infrastructure change approval process
Commitment coverage reviewed quarterly against utilization baseline
Unit economics (cost per request/customer/pipeline) tracked and dashboarded
Non-production environments scheduled or ephemeral by default
Data transfer architecture reviewed for cross-AZ and NAT optimization
Closing Principle
Cost optimization is not a project with an end date. It's a continuous system that compounds—or decays—based on the feedback loops you maintain.
The goal is never "cheapest at any cost." The goal is predictable spend that enables sustainable engineering velocity. When finance can forecast confidently and engineering can attribute costs to workloads, optimization becomes a shared discipline rather than a periodic fire drill.