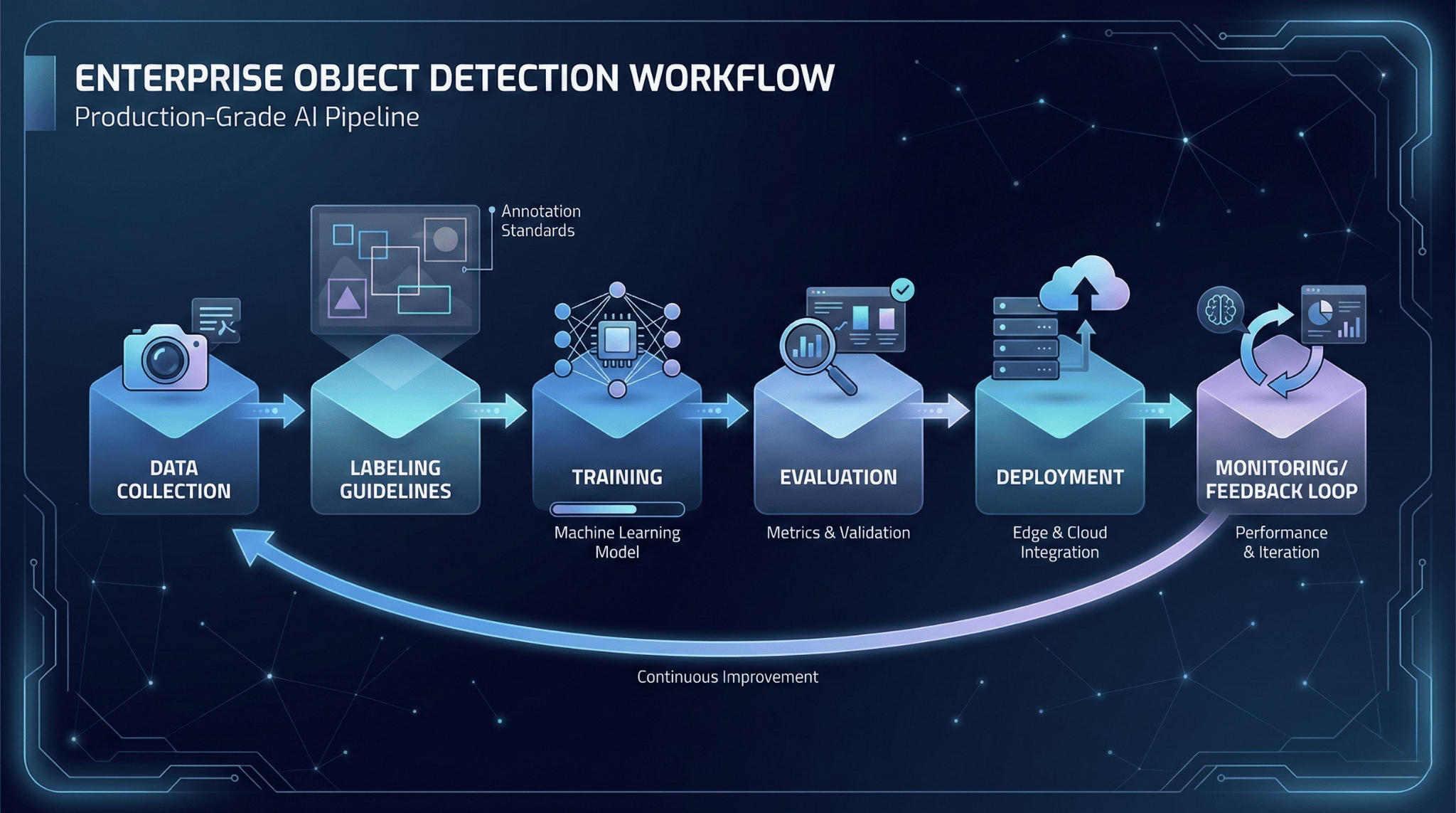
Why Object Detection Projects Fail in Production
Most production object detection failures aren’t model failures. They’re system failures: the model may be fine, but the surrounding workflow—data coverage, labeling contracts, evaluation discipline, deployment consistency, and monitoring—is incomplete.
A common pattern: a team achieves strong mAP on a held-out test set, deploys to production, and watches performance degrade within weeks. The causes are predictable—dataset shift between training and real-world conditions, inconsistent labeling that teaches ambiguous boundaries, edge cases that never appeared in training data, and absent monitoring that lets problems compound silently.
Success in production object detection is not about benchmark scores. It’s about operational reliability: consistent performance across real operating conditions, graceful handling of uncertainty, and sustainable maintenance over time.
Define the Problem as a Specification
Before any data collection or model selection, write a specification. This becomes the contract between your team and the system you’re building.
Objects and classes
Define exactly what constitutes each class. “Vehicle” is ambiguous—does it include motorcycles? Partially visible trucks? Parked cars versus moving ones? Write explicit inclusion and exclusion criteria.
Operating conditions
Document expected camera angles, lighting ranges, resolution, and occlusion patterns. A model trained on daytime footage will struggle at dusk—and will behave differently on a new camera with different optics.
Constraints
Specify latency requirements (p95, not average), target hardware (edge GPU, CPU, or cloud inference), and cost boundaries. These constraints will eliminate entire families of architectures before you write any training code.
Output contract
Define what the model returns and how downstream systems consume it:
bounding boxes + class labels + confidence scores,
coordinate format (e.g., xyxy vs xywh) and image scaling assumptions,
post-processing behavior (NMS and IoU thresholding),
and thresholding strategy (fixed cutoff vs per-class thresholds).
Failure modes
Describe expected behavior for unknown objects, low-confidence detections, and degradation over time. A production system needs fallback behavior—not just predictions.
Data Workflow (Where Most Outcomes Are Determined)
Data quality determines production performance more than model architecture. Treat your data pipeline with the same rigor as your deployment pipeline.
Collection and coverage
Build a data collection plan that covers operating conditions systematically. If the system runs across multiple sites, collect from all of them. If lighting varies by season, plan for seasonal refreshes. Document data sources, consent/compliance requirements, and retention policies early.
Coverage is not just volume. It’s representation of the conditions that drive errors: low light, glare, motion blur, partial occlusion, small objects, crowded scenes, and camera-specific artifacts.
Labeling strategy (labeling is a contract)
Labeling guidelines are a contract. Vague instructions produce inconsistent labels, and inconsistent labels produce unreliable models. Write guidelines that resolve edge cases explicitly: how much occlusion disqualifies an object? What’s the minimum visible area for a valid box? How do you label truncated objects at image boundaries?
Measure inter-annotator agreement regularly. If two annotators disagree on the same image more than ~10–15% of the time, your guidelines need revision. Use active learning or uncertainty sampling to surface hard cases for expert review rather than treating all images equally.
Dataset splits and versioning
Standard train/validation/test splits are necessary but insufficient. Add a challenge set—a curated collection of difficult examples representing edge cases you expect in production. This set becomes your regression suite.
Prevent data leakage rigorously. Images from the same scene, camera, or time window should stay in the same split. A model that memorizes camera-specific artifacts will fail on new installations.
Version your datasets. When you retrain six months later, you need to know exactly what data produced your current production model—and what changed.
Model Selection and Training (Constraints First)
Choose your baseline detector based on constraints, not benchmarks. YOLO-family models often offer strong latency characteristics for edge deployment. Two-stage detectors like Faster R-CNN may provide better accuracy when latency budgets are more generous. Match the architecture to your hardware target and your latency specification.
Consider dataset size and class imbalance. Small datasets benefit more from transfer learning. Severe imbalance often requires loss balancing, sampling strategies, or label refinement to avoid a model that “learns the majority class” and looks good on average metrics.
Training discipline matters more than hyperparameter tuning. Use augmentations that reflect real-world variance—if cameras have auto-exposure, train with brightness and contrast augmentation. Apply early stopping based on validation mAP (and condition-sliced metrics), not training loss. Run sanity checks: can the model overfit a small subset perfectly? If not, something is broken.
Transfer learning from COCO or similar large-scale datasets provides a strong starting point for most applications. Fine-tuning from pretrained weights typically outperforms training from scratch unless your domain is radically different from natural images.
Evaluation and Error Analysis (Where Reliability Is Won)
Offline metrics are necessary but not sufficient. mAP compresses performance into a single number and can obscure what matters in production. Always examine per-class precision and recall and segment performance by operating condition (lighting, camera, object size, occlusion).
Thresholding and calibration
Model confidence is not automatically calibrated probability. Validate what a “0.7 confidence” detection actually means in your system. Choose operating points based on the real business trade-off: tolerance for false positives versus missed detections. In many systems, thresholds should be class-specific and condition-aware.
Error taxonomy
Categorize errors systematically:
localization errors (box position/size),
classification confusion (wrong class),
missed detections (false negatives),
duplicate detections (post-processing / NMS failures).
Each category implies a different remediation strategy: label policy changes, data enrichment, augmentation, post-processing tuning, or architectural adjustments.
Golden set + acceptance criteria
Build a golden set of examples with verified ground truth. Run it on every model candidate before deployment. Define acceptance criteria tied to your specification—not “mAP above 0.8” but “precision above 0.95 for Class A at the production confidence threshold under low-light conditions.”
This converts evaluation from “looks good” to a release gate you can enforce.
Deployment and Monitoring (Production Reality)
Deployment is where many “good models” lose accuracy quietly. Start by exporting to an inference-optimized format appropriate for your target hardware. ONNX provides portability; TensorRT offers NVIDIA-specific acceleration where applicable. If you consider quantization for edge deployment, measure impact on the challenge set, not only on average validation metrics.
Consistency is non-negotiable. Preprocessing must be identical between training and inference: resizing method, aspect ratio handling (letterbox vs stretch), normalization, and color space conversion. Small mismatches are a common source of silent regressions.
Treat rollout as a controlled experiment. Use shadow or canary deployment, and gate promotion on both:
offline regression (golden set + challenge set), and
live signals (confidence distribution shifts, p95 latency, error/OOM rates, and throughput).
Have rollback triggers defined before you ship. Production readiness isn’t only correctness—it’s controlled change.
Monitoring that predicts failure
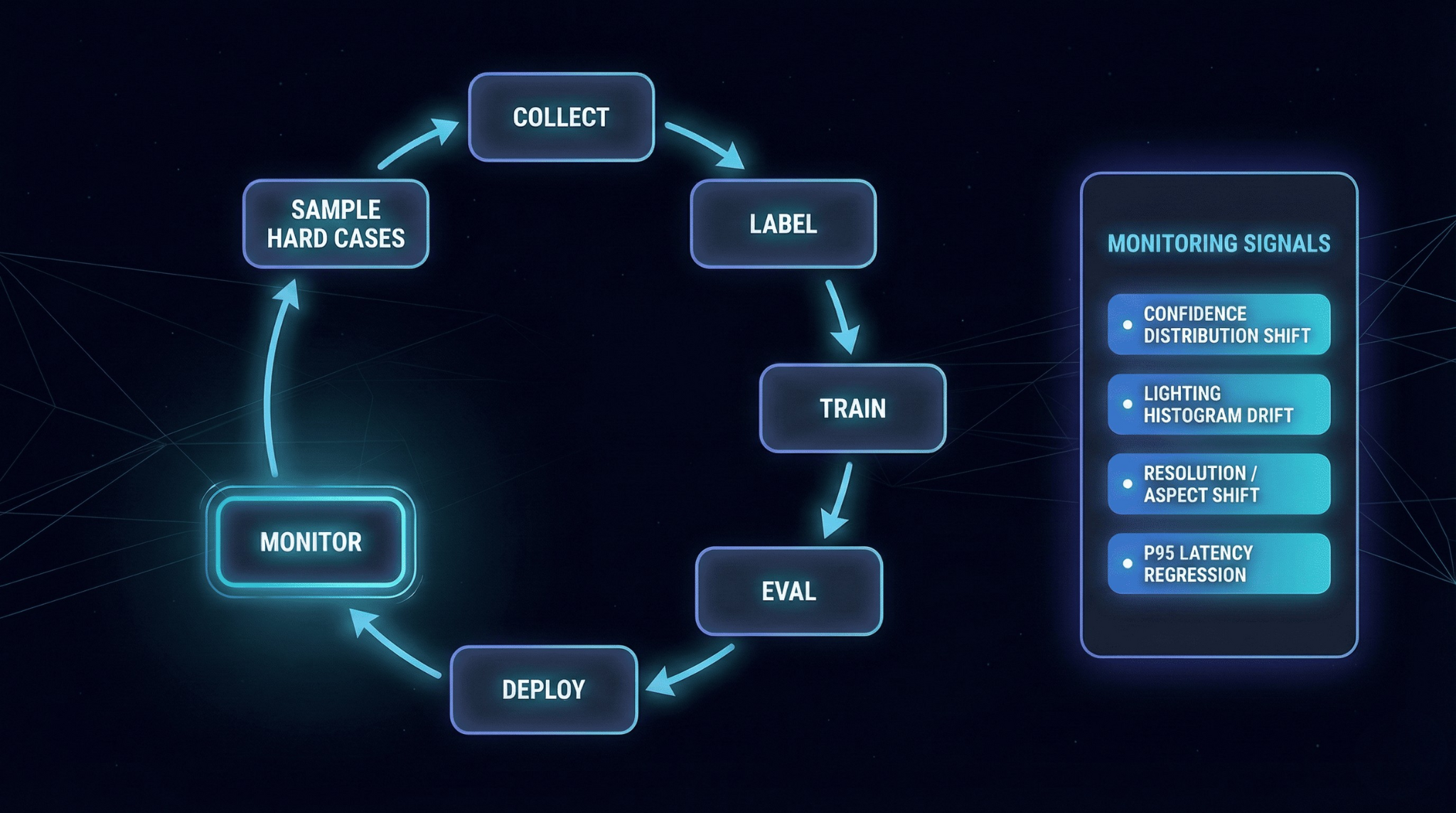
Monitoring is part of the production contract. Track signals that correlate with failures:
confidence score distribution drift,
changes in lighting/brightness histograms or camera metadata,
resolution shifts,
frequency of low-confidence detections,
and latency percentiles (p95/p99), not just averages.
Sample uncertain or novel cases for human review with a defined labeling SLA. This turns retraining into a pipeline—not an emergency response.
Establish a retraining cadence. Models degrade as operating conditions shift. Build the feedback loop—production sampling, labeling, retraining, evaluation, and safe rollout—before you need it.
Scenario: Warehouse Package Detection
Before: A package detection model achieved 0.91 mAP in offline evaluation. In production, precision dropped to 0.73 within two months. Investigation revealed seasonal lighting changes and new package types that weren’t represented in training data.
After: The team implemented systematic data collection across lighting conditions, added a challenge set covering expected edge cases, and established monthly monitoring of confidence distribution drift with sampling for human review. Six months post-deployment, precision stabilized at 0.89, with predictable seasonal variance addressed through quarterly retraining.
Production Checklist (Release Gate)
Define a written spec: classes, conditions, constraints, output contract, failure modes
Enforce labeling guidelines and track inter-annotator agreement (e.g., ≥ 85%)
Prevent leakage in splits (scene/camera/time) and maintain a challenge set
Set acceptance criteria tied to the spec and validate on a golden set before release
Deploy with consistency guarantees (preprocessing + post-processing) and controlled rollout/rollback
Monitor drift signals + latency percentiles and maintain a retraining feedback loop with data versioning
Closing Principles
Production object detection is data plus contracts plus operations. The model is only one component of a system that includes labeling pipelines, evaluation infrastructure, deployment consistency, and monitoring that turns drift into an actionable signal—not a surprise.
Start with a constrained baseline and a clear specification. Build a challenge set and golden set as your regression suite. Deploy with controlled rollout and rollback gates. Monitor the signals that predict failure and feed them back into a retraining loop.
Teams that succeed treat object detection as a production engineering system—repeatable, measurable, and maintainable—not a one-time modeling exercise.