
Introduction:
Turning website designs into working code can be tough because it involves understanding how visual elements are arranged and then coding them in a structured way. This often stops regular folks from creating their own web apps, even if they have good ideas.
However, multimodal LLMs, such as Flamingo, GPT-4V, and Gemini are now able to process visual and text input, generating text output. This includes addressing the long-standing challenge of Design2Code, where a screenshot of a website's design is used to automatically generate the full code implementation for the desired webpage.
A team of 5 AI experts has worked on a research to find out how far we are from automating front-end engineering. Their findings have yielded many intriguing insights. Visit the original article here.
Now, let's dive into it with Rockship.
Approach:
Test set preparation:
The overall goal is to obtain a set of well-formed webpages that represent diverse real-world use cases. The authors conducted an extensive manual curation process to only keep high-quality webpages with a variety of HTML and CSS elements involved.
In the end, they obtained 484 test examples that we use as our benchmark.
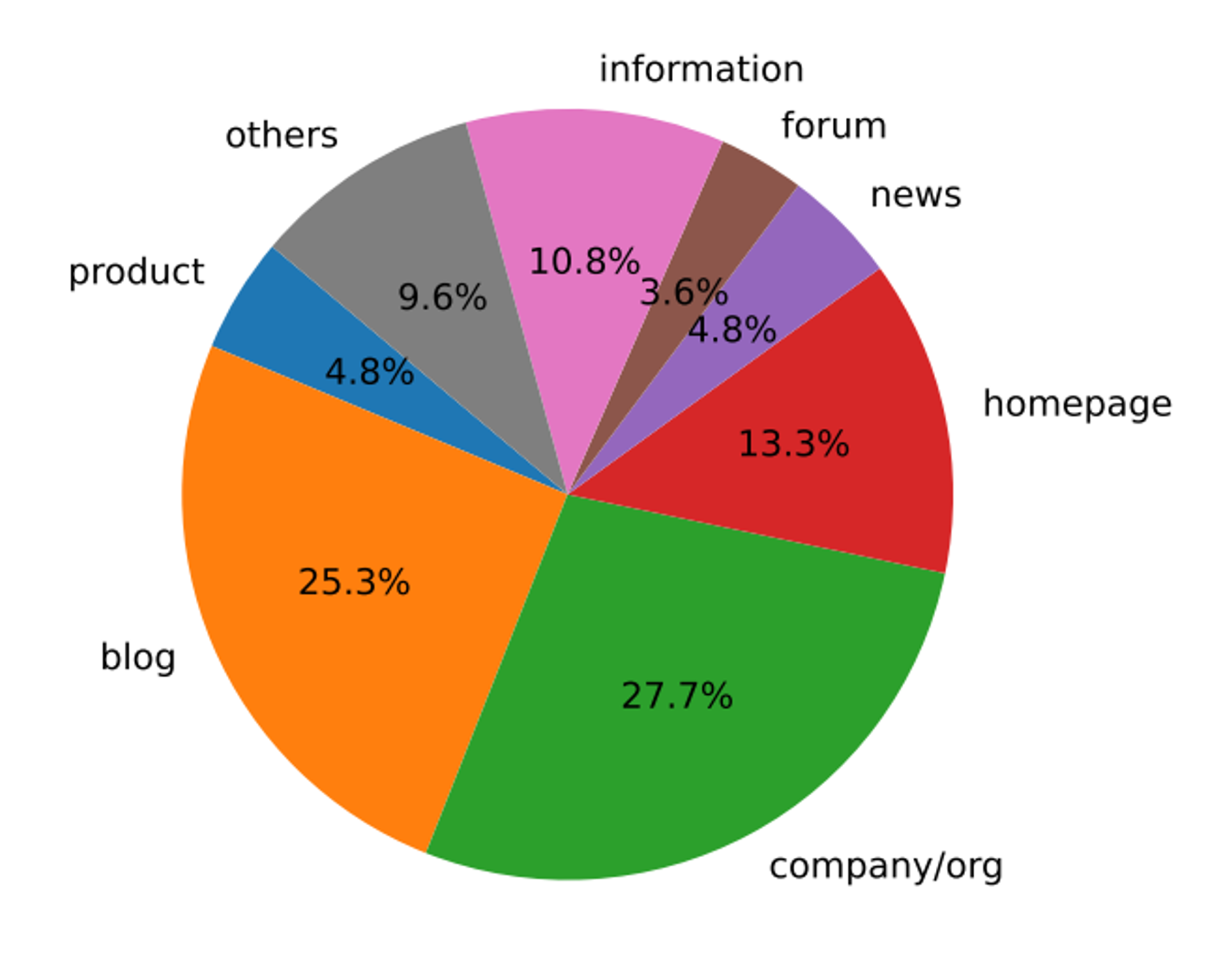
Fig 1. Main topics of the webpages in the benchmark. Source: https://arxiv.org/pdf/2403.03163.pdf
The most prominent genres are websites of companies or organizations, personal blogs, and homepages. Other genres include information-sharing sites (Wikipedia pages, FAQ pages, tax policy pages, online dictionaries), online forums, news article pages, and product description pages.
Model used:
- Commercial model: the authors experiment with GPT-4V B (OpenAI, 2023) and Gemini Pro Vision (Google, 2023) as the two best-performing publicly available APIs.
- Open source model:
- Design2Code-18B model: obtained by finetunning the CogAgent-18B model with the Huggingface WebSight dataset.
- The original CogAgent-18B model.
- The Huggingface WebSight VLM-8B model.
Prompting method:
- Direct prompting: The authors provide the model with a webpage screenshot, along with the following instruction:
You are an expert web developer who specializes in HTML and CSS. A user will provide you with a screenshot of a webpage. You need to return a single html file that uses HTML and CSS to reproduce the given website. Include all CSS code in the HTML file itself. If it involves any images, use "rick.jpg" as the placeholder. Some images on the webpage are replaced with a blue rectangle as the placeholder, use "rick.jpg" for those as well. Do not hallucinate any dependencies to external files. You do not need to include JavaScript scripts for dynamic interactions. Pay attention to things like size, text, position, and color of all the elements, as well as the overall layout. Respond with the content of the HTML+CSS file.
- Text-Augmented prompting: the authors extract all text elements from the original webpage first and append these texts after the instruction prompt along with the screenshot input.
- Self-revision prompting: The authors ask the models self-improve their own generations.
Metric:
The authors propose to automatically evaluate generated web pages by calculating the similarity between the screenshots of original webpages and that of generated web pages IG. They break it down into high-level visual similarity and low-level element matching.
- High-level Visual Similarity: Measure using the overall similarity of their CLIP embedding, denoted as CLIP
- Low-level Element Matching:
- Block-Match: assessing if the generated web pages replicate all visual elements from the reference webpage and avoiding the creation of non-existent elements.
- Text: measuring text similarity between the reference webpage and the generated one
- Position: measuring position similarity
- Color: measuring color similarity
Result:
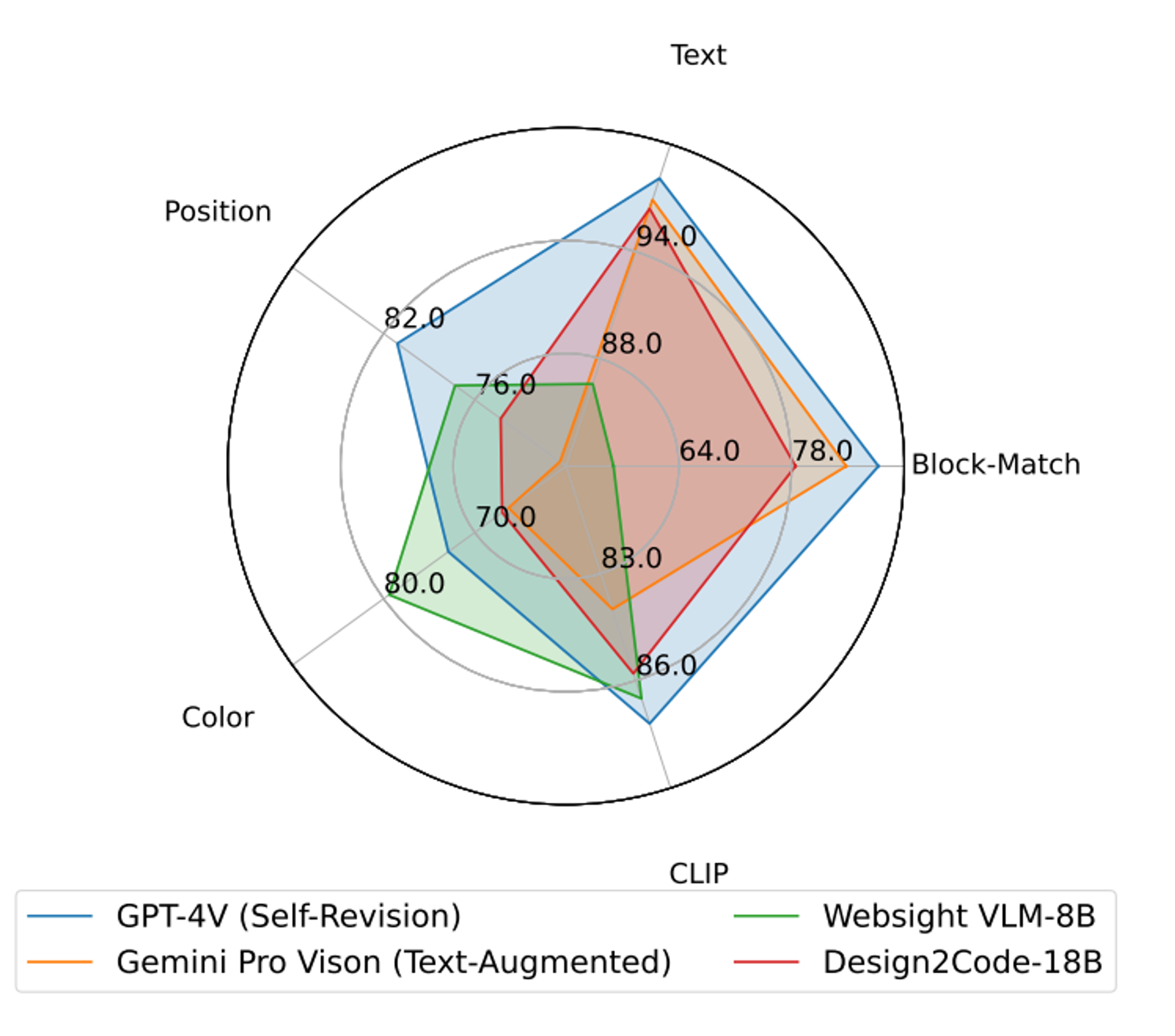
Fig 2. Performance of the benchmarked models. Source: https://arxiv.org/pdf/2403.03163.pdf
Automatic evaluation:
Some notable result:
- (1) GPT-4V is the best on all dimensions apart from color, on which WebSight VLM-8B is leading.
- (2) Finetuning achieves huge improvement on all dimensions as indicated by the comparison between Design2Code-18B and the base version CogAgent-18B.
- (3) The fine tuned Design Code-18B is better at block-match and text similarity, but worse at position similarity and color similarity as compared to WebSight VLM-8B.
Human evaluation:
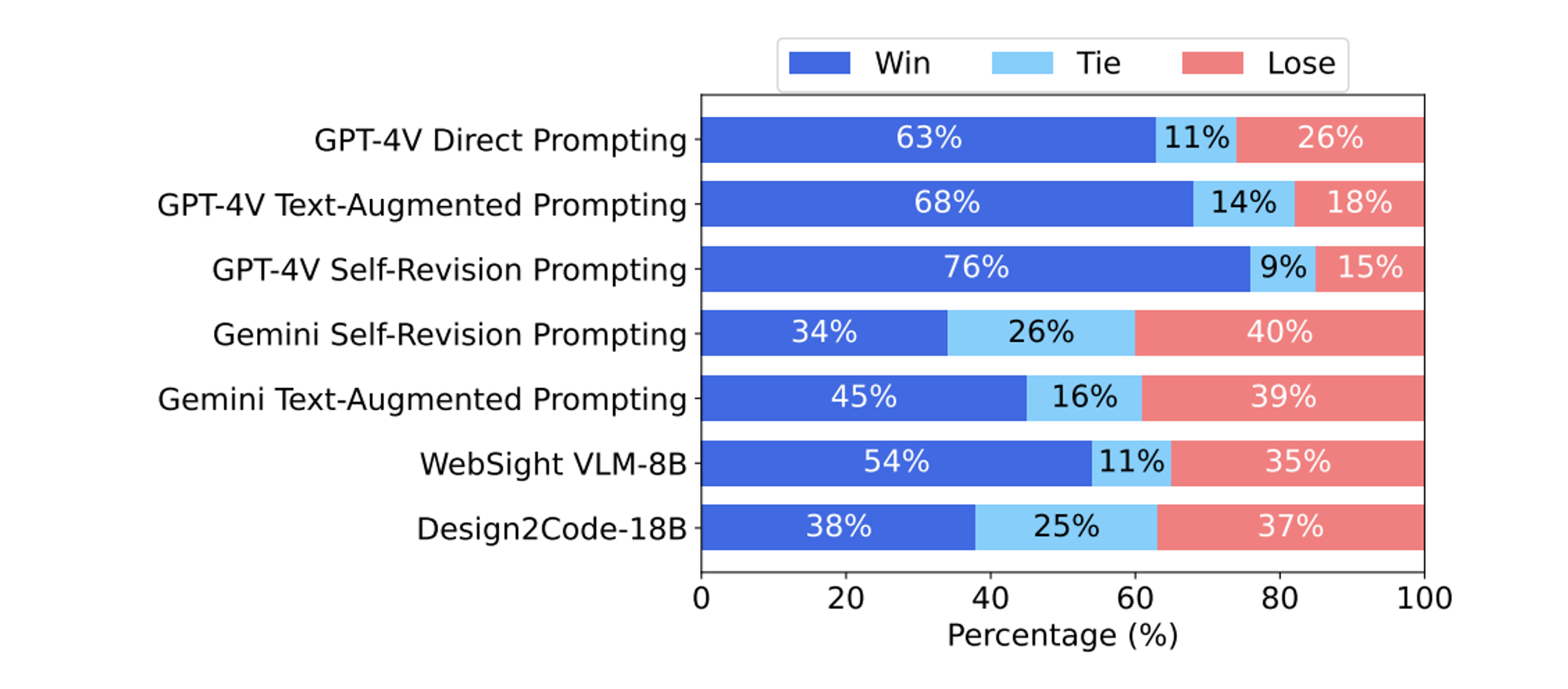
Fig 3. Human pairwise preference evaluation results with Gemini Pro Vision Direct prompting as the baseline. Source: https://arxiv.org/pdf/2403.03163.pdf
While automated metrics offer detailed insights into model performance, it's essential to consider human perspectives—the ultimate audience for these webpages. Using paid human annotators, we conducted evaluations to compare models and methods. Each question in the evaluations had input from 5 annotators, and results were determined by majority voting. The results are as following:
- (1) GPT-4V is substantially better than other baselines, while both text-augmented prompting and self-revision prompting can further improve over direct prompting.
- (2) Text-augmented prompting can slightly improve the Gemini direct prompting baseline, while further adding self-revision is not helpful.
- (3) WebSight VLM-8B performs better than Gemini direct prompting (54% win rate and 35% lose rate), suggesting that fine tuning on a large amount of data can match commercial models in specific domains.
- (4) Design2Code-18B matches the performance of Gemini Pro Vision direct prompting (38% win rate and 37% lose rate).
- (5) 49% of the AI-generated webpages are considered exchangeable with the reference webpages.
- (6) webpages generated by GPT-4V are preferred in 64% cases.
Conclusion:
The research shows great potential of Generative AI in automating front-end development, especially with the Design2Code task, where AI models convert visual designs into code. GPT-4V is currently the best-performing commercial model for the task. The fact that human evaluators preferring GPT-4V’s generated webpages over the originals in many cases suggests Generative AI could significantly impact front-end development, making it more accessible and efficient. However, challenges remain in element recall and layout generation. The future of Generative AI in this field looks promising, with ongoing improvements likely to enhance its capabilities further.
As a software services provider, we at Rockship celebrate every advancement in AI development. If you wish to build an app or a webpage using AI and low-code tools, book a call with us here for a solution that best serves your needs.


